Introduction to Tensor Processing Units
Originally written on April 15th, 2019.
Updated on:- December,2019
In this tutorial series, we will be taking a look into Tensor Processing Units or TPUs. I have divided the whole series into a number of posts.
What is a Tensor
Processing Unit?

A tensor processing unit
(TPU) is an AI accelerator application-specific integrated circuit (ASIC)
developed by Google specifically for neural network machine learning.
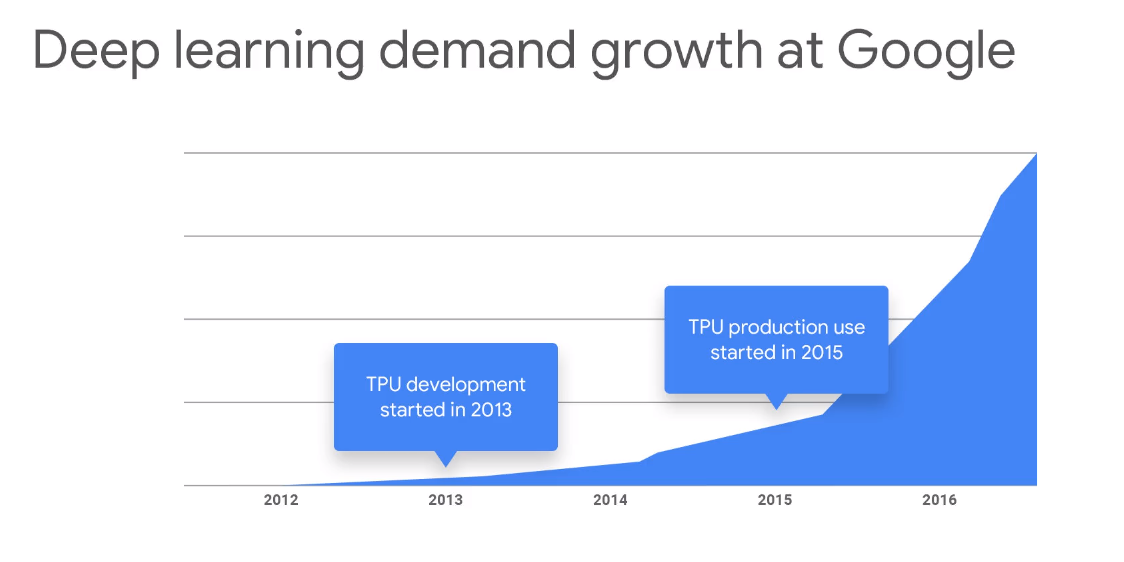
Google has been using TPUs in their
data centers since 2015. In the above graph you can see how the Deep Learning demand
at Google has increased since 2013. The TPU production started in 2015. Google
has designed them specifically for machine learning applications. They use them
for Google Translate, Photos, Search Assistant, Gmail, Cloud, etc.
Why did they make
their own chip?

1) Neural Networks in particular
almost always outperform other machine learning models if given enough data
& compute.
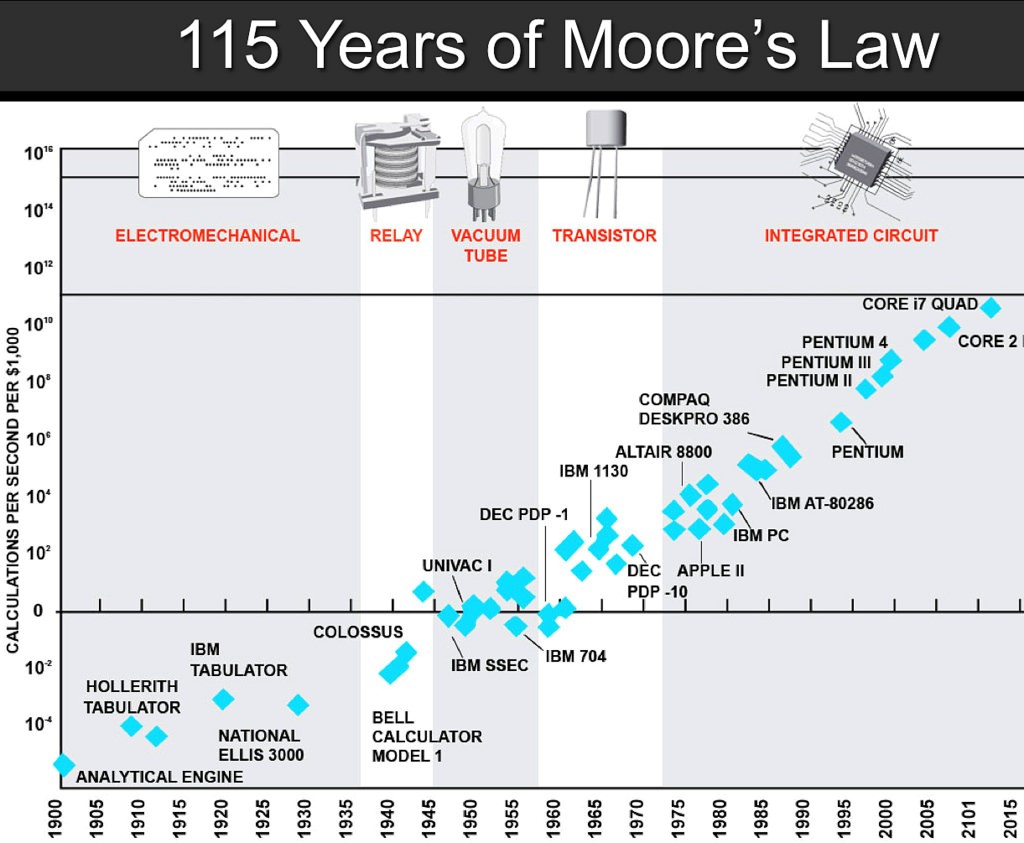
2) Neural networks require a lot of
compute!. As you can see in the above graph how the accuracy has improved since
Alexnet in 2012 and Deep Learning models need a lot of computation power. To
put it into a broader perspective, you can see how processing power
has increased in 115 years of Moore’s law. From relays and vacuum tubes to ICs.
RISC, CISC and the
TPU instruction set
Programmability was another important
design goal for the TPU. The TPU is not designed to run just one type of neural
network model. Instead, it's designed to be flexible enough to accelerate the
computations needed to run many different kinds of neural network models. Most
modern CPUs are heavily influenced by the Reduced Instruction Set Computer
(RISC) design style. With RISC, the focus is to define simple instructions
(e.g., load, store, add and multiply) that are commonly used by the majority of
applications and then to execute those instructions as fast as possible.
Complex Instruction Set Computer (CISC) style is used as the basis of the TPU
instruction set. A CISC design focuses on implementing high-level instructions
that run more complex tasks (such as calculating multiply-and-add many times)
with each instruction. Let's take a look at the block diagram of the TPU.

The TPU includes the following
computational resources:
Matrix Multiplier Unit (MXU): 65,536 8-bit
multiply-and-add units for matrix operations.
Unified Buffer (UB): 24MB of SRAM
that work as registers.
Activation Unit (AU): Hardwired
activation functions.
To control how the MXU, UB and AU
proceed with operations, there are a dozen high-level instructions specifically
designed for neural network inference. Five of these operations are highlighted
below.

This instruction set focuses
on the major mathematical operations required for neural network inference :
execute a matrix multiply between input data and weights and apply an
activation function. We will talk about the Neural Networks and the TPUs in the next part .
Citations:-
1) Cloud Google
Comments
Post a Comment